9 篇文章

評估 ChatGPT 和其他大型語言模型對於偵測假新聞的能力
評估 ChatGPT 和其他大型語言模型對假新聞的檢測能力背景簡介大型語言模型(LLMs)是自然語言處理(NLP)技術的進化,在快速生成與人類撰寫的文字相似的文字以及完成其他簡單的語言相關任務方面具有重要作用。OpenAI 開發的 ChatGPT 是一種高效的 LLM,自其公開發布以來已越來越受歡迎

重新思考 AI 基準:一篇新論文挑戰評估人工智慧的現狀
新論文挑戰評估人工智慧的現狀人工智慧(AI)近年來在實現許多複雜任務方面取得了顯著進展,這些任務曾經被認為是人類智慧的領域。從透過律師考試和高分透過 SAT,到掌握語言熟練度和診斷醫學影象,像 GPT-4 和 PaLM 2 等 AI 系統已經超越了人類在各個基準測試上的表現。基準測試基本上是衡量 A
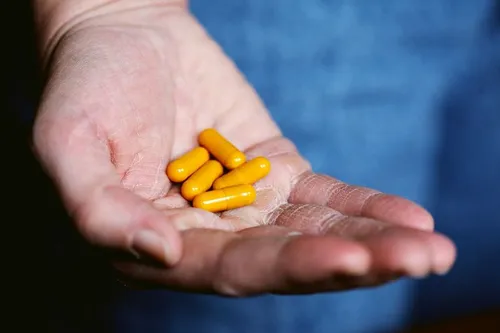
ChatGPT 對於回答困難的健康問題有多好?
ChatGPT 在回答健康問題上表現如何?人工智慧技術(AI)如 ChatGPT 有望在回答一些問題,例如“我該如何戒菸?”或者提供有關性侵犯的訊息和資源等方面有所作為。然而一項新研究顯示它們還沒有完全準備好。研究人員想要理解 ChatGPT 在為精神和身體健康服務尋求訊息和資源的人中的表現如何。他

暴雪嘉年華 2019:暗黑破壞神 IV 的初探與評估
暴雪娛樂未足夠審視之暗黑破壞神 IV 初探評估本文將對暴雪娛樂的暗黑破壞神 IV 進行初步探討,此星期六正式發售,可玩平臺包括 PlayStation、Xbox 和 PC。由於測評時缺少重要的特點:商店,加上時間太短以致無法評估修正進度的標準版,因此本文無法詳細審視遊戲,僅為尚未發售之先端看法。據報

Epic 獎勵 Fortnite 創作者,根據玩家遊戲體驗的長短作出評估
Epic 遊戲公司加固獎勵模式,創作者獲報酬方式改變近日 Epic 遊戲公司為《Fortnite》遊戲中的創作者們增加了一項新的“遊玩時間”評估指標,這是該公司在三月份推出更新創作者報酬制度時所做出的首個重大調整。創作者的獎勵將根據遊戲體驗的玩家流行度、遊戲留存率以及新增的遊玩時間進行評估,每個指標

人工智慧可以辨識表面裂痕模式來評估鋼筋混凝土結構受損情況
人工智慧可辨識鋼筋混凝土結構表面裂痕以評估受損程度近期美國多處結構崩塌事件,如佛羅裏達州的 Surfside、匹茲堡和紐約市,突顯了對美國老舊建築和基礎設施進行更頻繁和完整檢查的需求。但是現行檢查程式耗時且不一致,嚴重依賴檢查者的判斷力。 德雷謝爾大學和紐約州立大學布法羅分校的研究人員致力於使用人工

「Barkour 基準測試評估四足機械人的靈活性」
四足機械人的靈活性測試新基準:Barkour 近年來機器人技術的發展速度驚人,許多機器人的外表和行為已經可與真實動物媲美。當中,四足機械人的發展尤其值得關注,因為它們為開發各種應用程式提供了研究運動學、穩定性和韌性的寶貴機會,例如災難應急、醫療治療、環境監測和監視。然而這種四足機械人的不斷增多也給研究

評估語言模型中的政治偏見
研究顯示語言模型存在政治偏見最新研究顯示 ChatGPT 和其他生成式人工智慧背後的語言模型存在政治偏見,並且可能與大眾的意見不一致。這些模型是基於從全球的書庫、網站和社交媒體上蒐集、新聞報導和演講文稿上提取的書面文字訓練出來的。現在斯坦福大學的新研究正好量化了這些模型在與美國不同族群意見匹配方面表

阿裏巴巴雲端拆分公司可作為評估其他主要參與者的一個好基準
阿裏巴巴的雲端拆分可能成為評估其他主要參與者的良好基準中國科技巨頭阿裏巴巴正在透過一系列舉措震撼其企業結構,讓其業務的大部分可以籌集資金,甚至可能上市。考慮到這個企業集團在 2023 年第一季度的收入僅增長了中等水平的 2%,而其盈利能力正在下降(經營利潤較去年同期下降了 9%),這可能並非一個壞主
- 人工智慧 (1756)
- AI (908)
- 投資 (729)
- 蘋果 (583)
- Google (570)
- 新創公司 (505)
- openAI (399)
- 社交媒體 (363)
- 亞馬遜 (338)
- 微軟 (327)
- 收購 (324)
- 應用程式 (319)
- 加密貨幣 (312)
- 融資 (308)
- 電動車 (301)
- 特斯拉 (298)
- 網路安全 (293)
- 技術 (282)
- Meta (276)
- 印度 (274)
- 遊戲 (266)
- 金融科技 (266)
- 美國 (265)
- chatGPT (264)
- 創業 (230)
- CEO (218)
- 科技 (216)
- 裁員 (212)
- TikTok (203)
- 新功能 (203)
- 創新 (201)
- 籌資 (200)
- 歐盟 (197)
- 科技新聞 (194)
- 機器學習 (193)
- 技術創新 (179)
- 合作 (174)
- 生成式人工智慧 (165)
- 風險投資 (162)
- Twitter (161)
- Instagram (157)
- 英國 (153)
- 估值 (150)
- Reddit (145)
- Nvidia (144)
- 機器人 (138)
- YouTube (138)
- 自動化 (137)
- 聊天機器人 (136)
- 新聞 (136)
- iPhone (135)
- 資料分析 (133)
- 2024 年 (132)
- 科技創新 (132)
- 公司 (130)
- 未來 (130)
- 測試 (128)
- 資金 (128)
- 籌集資金 (128)
- Netflix (127)
- 比特幣 (127)
- 新創企業 (126)
- 投資者 (123)
- Spotify (123)
- 資訊安全 (122)
- 企業 (121)
- 募資 (120)
- 未來科技 (118)
- Threads (117)
- 三星 (117)
- 支援 (115)
- 馬斯克 (113)
- 研究 (113)
- 初創企業 (113)
- wordpress (113)
- 調查 (108)
- 歐洲 (108)
- AI 技術 (104)
- 自動駕駛 (103)
- 2024 (102)
- 平臺 (102)
- 安全 (102)
- 推出 (100)
- 駭客 (98)
- 上市 (97)
- 太空探索 (96)
- 創作者 (93)
- 功能 (93)
- 挑戰 (93)
- Android (92)
- 生成式 AI (90)
- 升級 (89)
- 資金籌集 (88)
- web3 (88)
- 訴訟 (87)
- 擴充套件 (85)
- 駭客攻擊 (85)
- 基金 (84)
- 使用者 (83)
- 更新 (82)
- 競爭對手 (81)
- 手機 (81)
- SpaceX (81)
- Apple (80)
- WhatsApp (80)
- 員工 (79)
- 影響 (79)
- 深度學習 (79)
- 籌集 (78)
- 技術發展 (78)
- 中國 (78)
- 自然語言處理 (77)
- Waymo (77)
- AI 模型 (77)
- 區塊鏈 (77)
- IPO (76)
- 新創 (75)
- TechCrunch (75)
- 開發者 (74)
- 可持續發展 (74)
- Facebook (74)
- 科技巨頭 (73)
- 資料隱私 (73)
- 智慧家居 (73)
- 價格 (72)
- 環保 (72)
- 工具 (70)
- iOS (70)
- Xbox (69)
- Uber (69)
- 交易 (69)
- 市場 (68)
- 監管 (68)
- 競爭 (67)
- 優惠 (67)
- TechCrunchDisrupt (67)
- 創辦人 (67)
- 科技公司 (67)
- 創業公司 (66)
- 技術新聞 (66)
- 2023 年 (65)
- 評測 (65)
- 太空科技 (64)
- 廣告 (64)
- 福特 (63)
- 索尼 (63)
- 網路攻擊 (61)
- 影片 (59)
- 自駕車 (59)
- (59)
- 上線 (58)
- 投資策略 (58)
- 科技界 (58)
- 科技趨勢 (58)
- 埃隆·馬斯克 (58)
- 安全漏洞 (58)
- VisionPro (58)
- 伊隆·馬斯克 (57)
- 加州 (57)
- 風險 (56)
- Microsoft (56)
- Anthropic (56)
- 開源 (56)
- 資料保護 (56)
- 執行長 (56)
- 技術趨勢 (55)
- 電子商務 (55)
- 直播 (55)
- 宣布 (54)
- Bluesky (54)
- 關閉 (54)
- 警告 (53)
- iOS17 (53)
- X (53)
- 爭議 (53)
- 罰款 (53)
- Twitch (52)
- A 輪融資 (52)
- 探索 (52)
- FTC (52)
- 解決方案 (51)
- SEC (51)
- YCombinator (50)
- A16z (50)
- 辭職 (50)
- 銷售 (50)
- 健康科技 (49)
- AI 工具 (49)
- 風險管理 (49)
- 迪士尼 (49)
- Amazon (49)
- Adobe (49)
- 資料安全 (49)
- Cruise (48)
- iPhone15 (48)
- 矽谷 (48)
- 售價 (47)
- Windows11 (47)
- Rivian (47)
- 創新科技 (47)
- 創始人 (47)
- 手機遊戲 (47)
- 併購 (47)
- 電影 (46)
- 耳機 (46)
- 無人機 (46)
- 體驗 (46)
- 機器人技術 (46)
- 熱議 (46)
- 非洲 (46)
- 活動 (46)
- AppStore (46)
- 法國 (46)
- 籌款 (45)
- 軟體開發 (45)
- 元宇宙 (45)
- 應用 (45)
- 法律 (45)
- 服務 (44)
- 威脅 (44)
- 問題 (44)
- 獨角獸 (43)
- 預告片 (43)
- 報告 (43)
- 播客 (43)
- 真相 (43)
- 新時代 (43)
- 晶片 (43)
- 預測 (43)
- 計劃 (42)
- 隱私保護 (42)
- 遊戲開發 (42)
- 反壟斷 (42)
- Salesforce (42)
- 約束 (42)
- NASA (42)
- 汽車 (42)
- AI 助手 (42)
- 任天堂 (42)
- startup (42)
- Copilot (42)
- 虛擬實境 (42)
- 起訴 (41)
- Mastodon (41)
- CES2025 (41)
- Discord (41)
- 破產 (41)
- 成功 (41)
- scrum (41)
- AWS (41)
- 使用者體驗 (41)
- 合作夥伴 (41)
- NFT (41)
- 設計 (41)
- 監管機構 (41)
- 可再生能源 (41)
- 開發 (41)
- 新技術 (40)
- Roblox (40)
- 研究人員 (40)
- 新產品 (40)
- 軟體 (40)
- 突破 (40)
- 整合 (40)
- Solana (39)
- 模型 (39)
- Windows (39)
- 推特 (38)
- iPad (38)
- 舊金山 (38)
- 創投 (38)
- 禁止 (38)
- 特朗普 (38)
- 資料洩露 (37)
- AMD (37)
- 醫療科技 (37)
- 市場趨勢 (37)
- API (37)
- 股票 (37)
- PS5 (37)
- 曝光 (37)
- 發展 (36)
- 汽車產業 (36)
- Snapchat (36)
- 科技發展 (36)
- telegram (36)
- 隱私 (36)
- 增長 (36)
- 罷工 (35)
- USB-C (35)
- 全球 (35)
- 產品 (35)
- 封鎖 (35)
- 數位轉型 (35)
- 未來趨勢 (35)
- PlayStation (35)
- 科技產品 (35)
- 網路 (35)
- 漏洞 (35)
- 購買 (34)
- 股市 (34)
- Chrome (34)
- 法案 (34)
- PrimeDay (34)
- GenAI (34)
- TechCrunchDisrupt2024 (34)
- FTX (34)
- 資料中心 (34)
- 搜尋引擎 (34)
- SamAltman (34)
- 改變 (34)
- 趨勢 (34)
- 支付 (34)
- 訓練 (34)
- 氣候科技 (34)
- 氣候變遷 (34)
- 科技業 (33)
- 攻擊 (33)
- Coinbase (33)
- 通用汽車 (33)
- 協議 (33)
- 董事會 (33)
- 盈利 (33)
- 裝置 (33)
- Gemini (33)
- 數位化 (33)
- 發射 (33)
- 革命 (33)
- 效率提升 (33)
- 環境保護 (33)
- 解析 (32)
- 學習 (32)
- 熱潮 (32)
- 智慧手錶 (32)
- 金融 (32)
- ElonMusk (32)
- 故事 (32)
- AI 聊天機器人 (32)
- 折扣 (32)
- GitHub (32)
- 創新技術 (32)
- 出售 (32)
- 電池 (31)
- 擴大 (31)
- 計畫 (31)
- disrupt (31)
- Fisker (31)
- Cybertruck (31)
- 藝術家 (31)
- 故障 (31)
- 企業管理 (31)
- 商業策略 (31)
- 網站 (31)
- 風投 (31)
- 電動汽車 (31)
- 巨頭 (31)
- 美國政府 (31)
- SaaS (30)
- 震撼 (30)
- 銀行 (30)
- 修復 (30)
- LLM (30)
- 轉型 (30)
- 2025 年 (30)
- 拉丁美洲 (30)
- 加速 (30)
- EpicGames (30)
- 以太坊 (30)
- 安全性 (30)
- 追蹤 (30)
- 加拿大 (30)
- 電動腳踏車 (30)
- iPhone15Pro (30)
- 教育科技 (30)
- 社交網路 (30)
- 成長 (29)
- 智慧裝置 (29)
- 英特爾 (29)
- 研發 (29)
- 種子輪融資 (29)
- 智慧 (29)
- 資料 (29)
- X 公司 (29)
- 社交平臺 (29)
- 資料外洩 (29)
- 瀏覽器 (29)
- 青少年 (29)
- 好萊塢 (29)
- PayPal (28)
- 以色列 (28)
- 商業新聞 (28)
- 種子融資 (28)
- VR (28)
- 大型語言模型 (28)
- B 輪融資 (28)
- Stripe (28)
- 智慧手機 (28)
- 合併 (28)
- 蘋果公司 (28)
- 娛樂 (28)
- DeepMind (28)
- BING (27)
- 生成式 (27)
- 革新 (27)
- 智慧眼鏡 (27)
- Databricks (27)
- 創業家 (27)
- 軟體更新 (27)
- 勒索軟體 (27)
- 團隊 (27)
- 演算法 (27)
- 創業者 (27)
- 訊息 (27)
- 智慧科技 (27)
- 竊取 (27)
- 日本 (27)
- 加密 (27)
- 新加坡 (27)
- 語言模型 (27)
- 控告 (27)
- iOS18 (27)
- 駭客入侵 (26)
- 數位行銷 (26)
- 觀看 (26)
- 最新訊息 (26)
- 資料庫 (26)
- 報導 (26)
- 發布 (26)
- 市場分析 (26)
- 失敗 (26)
- 抖音 (26)
- 人工智慧技術 (26)
- 財經 (26)
- 驚喜 (26)
- 禁令 (26)
- Alexa (26)
- Gmail (26)
- 專訪 (26)
- 肯亞 (26)
- IBM (26)
- 幣安 (26)
- 俄羅斯 (26)
- 生產 (26)
- 募集 (26)
- 資料洩漏 (26)
- WWDC (26)
- AI 功能 (25)
- 蘋果手錶 (25)
- 美元 (25)
- 遊戲產業 (25)
- 商業模式 (25)
- 音樂 (25)
- Fortnite (25)
- GoogleCloud (25)
- 德國 (25)
- 相機 (25)
- 下滑 (25)
- 崛起 (25)
- 客戶 (25)
- 價值 (25)
- GPT-4 (25)
- 澳洲 (25)
- Slack (25)
- 取消 (25)
- 選擇 (25)
- 擴增實境 (24)
- 機器人計程車 (24)
- 高管 (24)
- GM (24)
- technology (24)
- 投資趨勢 (24)
- 雲端 (24)
- Unity (24)
- 第二季 (24)
- 刪除 (24)
- 開放 AI (24)
- 原因 (24)
- 新科技 (24)
- 科技產業 (24)
- 音樂串流 (24)
- 解僱 (24)
- 外洩 (24)
- Zoom (24)
- Figma (24)
- 未來發展 (24)
- 軟銀 (24)
- 虛擬現實 (24)
- 品牌 (23)
- 高層 (23)
- 太空任務 (23)
- FCC (23)
- 資金支援 (23)
- Sony (23)
- 政治 (23)
- LLMs (23)
- 降價 (23)
- 白宮 (23)
- 事件 (23)
- 政府 (23)
- 招聘 (23)
- 巴西 (23)
- 搜尋 (23)
- 教育 (23)
- AR (23)
- 策略 (23)
- 入侵 (22)
- 太陽能 (22)
- YC (22)
- Intel (22)
- 延遲 (22)
- 變革 (22)
- 心理健康 (22)
- 免費 (22)
- 技術分析 (22)
- X 平臺 (22)
- 電視 (22)
- 打擊 (22)
- 人形機器人 (22)
- 解決問題 (22)
- DeepSeek (22)
- 印度市場 (22)
- Lyft (21)
- 最佳化 (21)
- 創意 (21)
- 聯合創始人 (21)
- 豐田 (21)
- 科技行業 (21)
- 離職 (21)
- 個人資料 (21)
- AI 應用 (21)
- Mac (21)
- 紐約 (21)
- Xai (21)
- 專家 (21)
- GPU (21)
- ActivisionBlizzard (21)
- 紐約市 (21)
- 抗議 (21)
- 評估 (21)
- 拜登政府 (21)
- Perplexity (21)
- 競賽 (21)
- 量子計算 (21)
- 氣候變化 (21)
- 擴張 (21)
- iMessage (21)
- 損失 (21)
- 會議 (21)
- 召回 (21)
- 關注 (21)
- 間諜軟體 (21)
- Disrupt2024 (20)
- 蘋果產品 (20)
- AppleWatch (20)
- 零日漏洞 (20)
- 網際網路 (20)
- XboxGamePass (20)
- CES2024 (20)
- 回歸 (20)
- 農業科技 (20)
- LG (20)
- Starlink (20)
- 潛力 (20)
- 無人駕駛 (20)
- 暫停 (20)
- Substack (20)
- 改進 (20)
- 數位貨幣 (20)
- 使用 (20)
- 未來展望 (20)
- CrowdStrike (20)
- 訂閱 (20)
- MetaQuest3 (20)
- LinkedIn (20)
- 山姆·班克曼-弗裏德 (20)
- 財經新聞 (20)
- 揭祕 (20)
- 筆記型電腦 (20)
- App (20)
- 3D 列印 (20)
- 開發人員 (20)
- 展示 (20)
- 科技裁員 (20)
- 就業市場 (20)
- 預告 (20)
- 問題解決 (20)
- 監控 (20)
- 信任 (20)
- 拜登 (20)
- Tinder (20)
- 推薦 (20)
- 新款 (20)
- 推文 (20)
- MrBeast (20)
- 多元化 (20)
- 版主 (19)
- 計程車 (19)
- 社群媒體 (19)
- 擔憂 (19)
- Shein (19)
- 韓國 (19)
- 目標 (19)
- 藝術 (19)
- 媒體 (19)
- 測試版 (19)
- 無線耳機 (19)
- 時尚 (19)
- 沃爾瑪 (19)
- Pixel8 (19)
- Firefly (19)
- Snap (19)
- 客戶資料 (19)
- 智慧助手 (19)
- 危機 (19)
- 健康 (19)
- Ubisoft (19)
- AI 生成 (19)
- Pixel (19)
- 批準 (19)
- 區塊鏈技術 (19)
- 製造商 (19)
- Shopify (19)
- 太空 (19)
- 電子遊戲 (19)
- Grok (19)
- Switch (18)
- 西班牙 (18)
- 分享 (18)
- 法律問題 (18)
- investment (18)
- 強化 (18)
- Snowflake (18)
- 社會影響 (18)
- 社群 (18)
- 遊戲體驗 (18)
- 雲端計算 (18)
- 美國市場 (18)
- 科學家 (18)
- 紐約時報 (18)
- 穩定幣 (18)
- Automattic (18)
- 電商 (18)
- 新品發布 (18)
- 政策 (18)
- 科技投資 (18)
- 技術問題 (18)
- 指控 (18)
- 惡意軟體 (18)
- Arm (18)
- 選舉 (18)
- 人類 (18)
- 預期 (18)
- 市值 (18)
- AI 訓練 (18)
- 金融市場 (18)
- 頭戴式裝置 (18)
- 技術更新 (18)
- 製造 (18)
- 自駕卡車 (18)
- 業務 (18)
- 登場 (18)
- Airbnb (18)
- 中小企業 (18)
- VanMoof (18)
- 人力資源 (18)
- SBF (18)
- SamBankman-Fried (18)
- 新資金 (18)
- 本田 (18)
- 偏見 (18)
- 開放 (18)
- 分析 (18)
- MacBookAir (18)
- 開放人工智慧 (18)
- 創作 (17)
- 作家 (17)
- Starfield (17)
- EA (17)
- FinTech (17)
- 實驗 (17)
- 內容創作 (17)
- 經濟 (17)
- 建立 (17)
- 新基金 (17)
- 聯邦貿易委員會 (17)
- 比較 (17)
- 消費者 (17)
- 投資機會 (17)
- 付費 (17)
- 詐騙 (17)
- 技巧 (17)
- 訂閱服務 (17)
- 決勝時刻 (17)
- 有聲書 (17)
- 工作 (17)
- 減少 (17)
- 馬克·祖克柏 (17)
- 預訂 (17)
- 神經網路 (17)
- 智慧財產權 (17)
- 投票 (17)
- 和解 (17)
- 商業 (17)
- FBI (17)
- 內容 (17)
- 即時通訊 (17)
- 參議院 (17)
- 藍色起源 (17)
- 營收 (17)
- OnePlus (17)
- Siri (17)
- 機會 (17)
- 生態系統 (17)
- SteamDeck (17)
- AI 發展 (17)
- 最高法院 (17)
- 美國司法部 (17)
- 新趨勢 (17)
- 討論 (17)
- Verizon (16)
- 富士康 (16)
- 困境 (16)
- 科技活動 (16)
- 物流 (16)
- 提升 (16)
- 限時優惠 (16)
- 遊戲新聞 (16)
- 23andMe (16)
- 電腦 (16)
- 科幻 (16)
- 登陸 (16)
- AppleVisionPro (16)
- AI 監管 (16)
- 交通科技 (16)
- 退出 (16)
- 改革 (16)
- C 輪融資 (16)
- 奈及利亞 (16)
- 下載 (16)
- 承諾 (16)
- 玩家 (16)
- 虛擬貨幣 (16)
- WPEngine (16)
- 雲端服務 (16)
- 資金募集 (16)
- 綠色能源 (16)
- 獨家報導 (16)
- AI 驅動 (16)
- 烏克蘭 (16)
- 司法部 (16)
- 輕鬆 (16)
- 模型訓練 (16)
- 執行 (16)
- 系統 (16)
- Brex (16)
- 資料處理 (16)
- Sonos (16)
- 種子輪 (16)
- 高通 (16)
- 作業系統 (16)
- Byju's (16)
- pitchdeck (16)
- 商機 (16)
- 最新 (16)
- 汽車科技 (15)
- Instacart (15)
- 審判 (15)
- 洛杉磯 (15)
- 新聞標題 (15)
- 中東 (15)
- Valve (15)
- 技術革新 (15)
- 充電標準 (15)
- 對話 (15)
- 個性化 (15)
- Steam (15)
- fundraising (15)
- 投訴 (15)
- 新增 (15)
- 結束 (15)
- 設計工具 (15)
- 共同創辦人 (15)
- 手機應用程式 (15)
- 倫理 (15)
- 獲利 (15)
- 管理 (15)
- 國會 (15)
- DoorDash (15)
- 印尼 (15)
- AI 晶片 (15)
- 指南 (15)
- 可靠性 (15)
- 照片 (15)
- iPhone16 (15)
- 替代方案 (15)
- 資料管理 (15)
- 創業故事 (15)
- 專注 (15)
- 行動 (15)
- 最佳 (15)
- T-Mobile (15)
- 加密技術 (15)
- 聲音 (15)
- 強大 (15)
- 阿裏巴巴 (15)
- 消失 (15)
- 國家 (15)
- 遊戲主機 (15)
- 充電器 (15)
- 保護 (15)
- 智慧型手機 (15)
- 軟體公司 (15)
- eBay (15)
- 動力 (15)
- 衛星 (15)
- Venmo (15)
- 應用商店 (15)
- Flipkart (15)
- 演員 (15)
- 促銷 (15)
- 協作 (15)
- 受害者 (15)
- 對決 (15)
- Pixel8Pro (15)
- 視訊通話 (15)
- 勒索軟體攻擊 (15)
- 專案 (15)
- 安全問題 (15)
- Worldcoin (15)
- 數位支付 (15)
- 混亂 (15)
- Samsung (15)
- GooglePixel8 (15)
- 數位資產 (15)
- 影響力 (15)
- 基礎設施 (15)
- 重組 (14)
- 未來交通 (14)
- Sequoia (14)
- 戰爭 (14)
- 螢幕 (14)
- 車輛 (14)
- 虛擬世界 (14)
- 首播 (14)
- 新篇章 (14)
- 位元組跳動 (14)
- 碳排放 (14)
- 工作效率 (14)
- 新紀元 (14)
- 揭曉 (14)
- 太空船 (14)
- 加速器 (14)
- Google 搜尋 (14)
- 寶可夢 (14)
- 勒索病毒 (14)
- 簡化 (14)
- Google 地圖 (14)
- Cohere (14)
- 釋出 (14)
- 資助 (14)
- Epic (14)
- 風險評估 (14)
- 顛覆 (14)
- 招募 (14)
- 亞特蘭大 (14)
- 揭露 (14)
- 增強現實 (14)
- MacBookPro (14)
- 供應商 (14)
- Niantic (14)
- Fitbit (14)
- Canva (14)
- 能源 (14)
- Binance (14)
- KaserFocus (14)
- 批評 (14)
- 多人遊戲 (14)
- 現代化 (14)
- 市場競爭 (14)
- 製作 (14)
- 充電 (14)
- 遊戲平臺 (14)
- reels (14)
- 扎克伯格 (14)
- 亞洲 (14)
- Bumble (14)
- GPT (14)
- 下一代 (14)
- ETF (14)
- 網路犯罪 (14)
- 汽車製造商 (14)
- 無人計程車 (14)
- 資訊科技 (14)
- Bard (14)
- PrimeVideo (14)
- 資訊 (14)
- AI 安全 (14)
- 工廠 (14)
- 收益 (14)
- 連結 (14)
- 羅技 (13)
- 效能提升 (13)
- 雲端運算 (13)
- AirPods (13)
- 旅行 (13)
- 蘋果 VisionPro (13)
- 供應鏈 (13)
- 進展 (13)
- GooglePlay (13)
- 企業家 (13)
- 機遇 (13)
- Ripple (13)
- 高科技 (13)
- AirPodsPro (13)
- 遊戲公司 (13)
- 領導力 (13)
- 合約 (13)
- 去中心化 (13)
- GooglePixel (13)
- 預購 (13)
- fediverse (13)
- 警方 (13)
- 購物 (13)
- 歷史 (13)
- 售出 (13)
- 金融服務 (13)
- 發表會 (13)
- 音樂產業 (13)
- TCDisrupt2023 (13)
- VC (13)
- 學生 (13)
- XRP (13)
- 風險投資家 (13)
- ElevenLabs (13)
- AI 法案 (13)
- 技術公司 (13)
- 秋季 (13)
- 特價 (13)
- 收費 (13)
- 樂高 (13)
- 安卓 (13)
- 改善 (13)
- Beeper (13)
- 食品科技 (13)
- 2025 (13)
- 工程師 (13)
- LockBit (13)
- Runway (13)
- SOL (13)
- 硬體 (13)
- 法官 (13)
- 假新聞 (13)
- 貸款 (13)
- 傳聞 (13)
- 沙烏地阿拉伯 (13)
- TheVerge (13)
- Atlassian (13)
- 智慧化 (13)
- 交易所 (13)
- 第三季 (13)
- Messenger (13)
- 信用卡 (13)
- Artifact (13)
- 十月 (13)
- Signal (13)
- 環保技術 (13)
- 審查 (13)
- 主管 (13)
- 資料竊取 (13)
- 音質 (13)
- Quest3 (13)
- 費用 (13)
- 注資 (13)
- 電子郵件 (13)
- 價格分析 (13)
- GoogleAI (13)
- TikTok 禁令 (13)
- 財務管理 (13)
- 健康追蹤 (13)
- Matter (13)
- 職業發展 (13)
- 便宜 (13)
- 生物科技 (13)
- 保時捷 (13)
- 漫威 (13)
- 哈馬斯 (13)
- 數位安全 (13)
- 1 億美元 (13)
- 使用者增長 (13)
- 準備 (13)
- 科技展覽 (13)
- 方法 (13)
- 太空產業 (13)
- Ford (13)
- 潮流 (13)
- 新車 (13)
- 醫療保健 (13)
- 電子產品 (13)
- 搜尋功能 (13)
- 非營利組織 (13)
- 回顧 (12)
- 終止 (12)
- 火箭實驗室 (12)
- 智慧交通 (12)
- 亞洲市場 (12)
- Reliance (12)
- 旅遊 (12)
- 太空旅行 (12)
- 賺錢 (12)
- 科技未來 (12)
- 利潤 (12)
- 錢包 (12)
- B2B (12)
- 預覽 (12)
- innovation (12)
- 技術挑戰 (12)
- 交通 (12)
- 小型企業 (12)
- 基金籌集 (12)
- 蓬勃發展 (12)
- 月球 (12)
- Robinhood (12)
- UberEats (12)
- DeFi (12)
- VentureBeat (12)
- 新興市場 (12)
- 消費電子 (12)
- 新星 (12)
- 截止 (12)
- 人工智慧應用 (12)
- 重製版 (12)
- Kubernetes (12)
- 大型科技公司 (12)
- 總裁 (12)
- 人工智慧模型 (12)
- GoogleDeepMind (12)
- A 輪 (12)
- 技術應用 (12)
- 就業 (12)
- macOS (12)
- 事件分析 (12)
- SPAC (12)
- 基準測試 (12)
- 企業資料 (12)
- 辦公室 (12)
- 法庭 (12)
- 小工具 (12)
- 投資風險 (12)
- 上訴 (12)
- 溝通 (12)
- Tumblr (12)
- 開源軟體 (12)
- 外觀 (12)
- 優勢 (12)
- 協助 (12)
- 申請 (12)
- Starship (12)
- Activision (12)
- 取證 (12)
- 動畫 (12)
- tagnames (12)
- 數位媒體 (12)
- 買家 (12)
- 性別平等 (12)
- HuggingFace (12)
- 開發工具 (12)
- RCS (12)
- 規則 (12)
- 收入 (12)
- 教學 (12)
- 使用者資料 (12)
- 資安 (12)
- 聯盟 (12)
- 勝訴 (12)
- 物聯網 (12)
- 月費 (12)
- 機械鍵盤 (12)
- 頭戴裝置 (12)
- 房地產 (12)
- 搜尋結果 (12)
- 超級電腦 (12)
- 速度 (12)
- 企業動態 (12)
- 省錢 (12)
- 遊戲開發者 (12)
- 回應 (12)
- 領袖 (12)
- 網站開發 (12)
- AT&T (12)
- 紀錄 (12)
- 墨西哥 (12)
- 經濟影響 (12)
- 創業投資 (12)
- 朋友 (12)
- 程式設計 (12)
- 科學研究 (12)
- 生產力 (12)
- VBTransform (12)
- NBA (12)
- 臺灣 (12)
- 自駕計程車 (12)
- 危險 (12)
- 粉絲 (12)
- 部署 (12)
- 重啟 (12)
- 北韓 (12)
- 倫敦 (12)
- 2023 (12)
- 重新設計 (12)
- 市場策略 (12)
- 家庭 (12)
- 進軍 (12)
- 網紅 (11)
- 價格上漲 (11)
- 使用者數 (11)
- 合夥人 (11)
- 5G (11)
- GitHubCopilot (11)
- 兒童 (11)
- 川普 (11)
- 電腦視覺 (11)
- 環保科技 (11)
- 飆升 (11)
- 宣稱 (11)
- 網站安全 (11)
- Flexport (11)
- 大眾 (11)
- 經典遊戲 (11)
- Mistral (11)
- Swiggy (11)
- 升級版 (11)
- 健康管理 (11)
- 期待 (11)
- 音樂平臺 (11)
- 任務 (11)
- 太空技術 (11)
- 負責任 (11)
- PC (11)
- Wiz (11)
- 技術突破 (11)
- 聯想 (11)
- 技術倫理 (11)
- 價格調整 (11)
- 女性 (11)
- Z 世代 (11)
- 移除 (11)
- 團隊合作 (11)
- 關係 (11)
- 紐西蘭 (11)
- 分析師 (11)
- 訂閱者 (11)
- 新品 (11)
- gaming (11)
- 資料科學 (11)
- 演講 (11)
- 探討 (11)
- 談判 (11)
- 影象生成 (11)
- Photoshop (11)
- 約會應用 (11)
- 沃爾沃 (11)
- 聊天 (11)
- 孩子 (11)
- Pinterest (11)
- StartupBattlefield (11)
- Plaid (11)
- 崩潰 (11)
- 波士頓動力 (11)
- PC 遊戲 (11)
- MicrosoftTeams (11)
- 星際大戰 (11)
- AI 新創公司 (11)
- 交通運輸 (11)
- 減碳 (11)
- 卡車 (11)
- 娛樂產業 (11)
- 摺疊手機 (11)
- 私有化 (11)
- 創業精神 (11)
- 開發者工具 (11)
- 表現 (11)
- 種子資金 (11)
- 投資新聞 (11)
- 大揭祕 (11)
- 首次公開募股 (11)
- 現代汽車 (11)
- Techstars (11)
- Visa (11)
- AI 倫理 (11)
- 虧損 (11)
- 航空航天 (11)
- 壟斷 (11)
- PixelWatch2 (11)
- Ramp (11)
- 位元幣 (11)
- 恢復 (11)
- 製造業 (11)
- 網站建設 (11)
- 決策 (11)
- Prime 會員 (11)
- 安全措施 (11)
- NFL (11)
- iRobot (11)
- 風險投資公司 (11)
- 工作流程 (11)
- 司機 (11)
- Apollo (11)
- 醫療創新 (11)
- 無廣告 (11)
- 下降 (11)
- 黑鏡 (11)
- Claude (11)
- 影片製作 (11)
- 規定 (11)
- ServiceNow (11)
- 研究發現 (11)
- 產品發布 (11)
- 貼文 (11)
- 短影片 (11)
- 道歉 (11)
- 節能 (11)
- 語言學習 (11)
- 亞馬遜 PrimeDay (11)
- 德州 (11)
- 前景 (11)
- 英偉達 (11)
- 企業發展 (11)
- PlayStationPlus (11)
- 重塑 (11)
- 倒閉 (11)
- 恐懼 (11)
- 拉斯維加斯 (11)
- Roku (11)
- 現貨 ETF (11)
- 荷蘭 (10)
- Sora (10)
- Mozilla (10)
- 財富管理 (10)
- WeRide (10)
- 加密貨幣交易所 (10)
- 新版本 (10)
- 下載量 (10)
- 重要性 (10)
- 漲價 (10)
- 垃圾郵件 (10)
- 商家 (10)
- Minecraft (10)
- 隱私權 (10)
- 系列 (10)
- 效能 (10)
- 全電動 (10)
- MOVEit (10)
- 數 (10)
- 祕密 (10)
- 募集資金 (10)
- Ring (10)
- 自動駕駛汽車 (10)
- 商店 (10)
- 驅動 (10)
- 串流 (10)
- 機器人公司 (10)
- 歐洲市場 (10)
- 付費使用者 (10)
- 社會責任 (10)
- MistralAI (10)
- BeReal (10)
- DOGE (10)
- 上漲 (10)
- 世界 (10)
- 企業新聞 (10)
- 網頁 (10)
- Accel (10)
- Better.com (10)
- 新潮流 (10)
- 控制 (10)
- 反壟斷調查 (10)
- 安裝 (10)
- 伺服器 (10)
- PhonePe (10)
- 通行證 (10)
- Everlodge (10)
- 企業解決方案 (10)
- 登入 (10)
- 版權 (10)
- 標題 (10)
- 能源轉型 (10)
- XboxSeriesX (10)
- CodeConference (10)
- AI 平臺 (10)
- 快速充電 (10)
- 傳言 (10)
- 遠端工作 (10)
- 進化 (10)
- Patreon (10)
- Opera (10)
- GoogleChrome (10)
- TheDeanBeat (10)
- 平板電腦 (10)
- 外掛 (10)
- 盛事 (10)
- 裁員趨勢 (10)
- 環境影響 (10)
- 密碼 (10)
- Canoo (10)
- 希望 (10)
- 顯示器 (10)
- 技術競爭 (10)
- 股權 (10)
- 人工智慧安全 (10)
- 比特幣價格分析 (10)
- Synapse (10)
- 獎勵 (10)
- 震撼登場 (10)
- 電競 (10)
- RPG (10)
- Peacock (10)
- 風潮 (10)
- Mastercard (10)
- Chromebook (10)
- 編輯探索 (10)
- Oracle (10)
- 地圖 (10)
- 餐飲業 (10)
- 手機應用 (10)
- Arc (10)
- MaxQ (10)
- 自駕技術 (10)
- 聘請 (10)
- 主題演講 (10)
- 半導體 (10)
- GoogleGemini (10)
- 資金注入 (10)
- 資料集 (10)
- 可持續能源 (10)
- 產品開發 (10)
- Klarna (10)
- 資產 (10)
- 門票 (10)
- 藍芽 (10)
- TechCrunchEarlyStage (10)
- 以太幣 (10)
- 技術長 (10)
- 影片生成 (10)
- 高盛 (10)
- 原因分析 (10)
- 第三方應用程式 (10)
- 商業發展 (10)
- 共和黨 (10)
- 火箭發射 (10)
- iFixit (10)
- 遊戲業 (10)
- 提案 (10)
- 反彈 (10)
- 個人化 (10)
- 透明度 (10)
- 存取 (10)
- 華爾街 (10)
- 股份 (10)
- iPhone15ProMax (10)
- AI 公司 (10)
- Pornhub (9)
- 遊戲玩家 (9)
- 錯誤 (9)
- 議程 (9)
- 語音助手 (9)
- 新工具 (9)
- 國際關係 (9)
- 競爭法 (9)
- PeakXV (9)
- 時間管理 (9)
- 洩漏 (9)
- 空中計程車 (9)
- 人機互動 (9)
- 串流服務 (9)
- 300 萬美元 (9)
- 上架 (9)
- 離開 (9)
- 遊戲設計 (9)
- 最新動態 (9)
- MagSafe (9)
- 便利 (9)
- 奧斯汀 (9)
- 競爭者 (9)
- 產業趨勢 (9)
- 風險投資者 (9)
- 技術合作 (9)
- 削減 (9)
- 解鎖 (9)
- 新動向 (9)
- 移動應用程式 (9)
- Model3 (9)
- 巴勒斯坦 (9)
- FoundersFund (9)
- 義大利 (9)
- 初創 (9)
- 下架 (9)
- 航空業 (9)
- 冠軍 (9)
- 維修 (9)
- 神祕面紗 (9)
- 隱私問題 (9)
- CES (9)
- C 輪 (9)
- socialmedia (9)
- 圖片 (9)
- 行銷 (9)
- 寶馬 (9)
- 投資組合 (9)
- 反對 (9)
- 聯合創辦人 (9)
- 頻道 (9)
- 互動 (9)
- 新體驗 (9)
- 氣候基金 (9)
- MosaicML (9)
- 印度經濟 (9)
- 新規定 (9)
- SB1047 (9)
- 金額 (9)
- 瑞典 (9)
- BMW (9)
- Edge (9)
- 雲端儲存 (9)
- 推動 (9)
- 程式碼生成 (9)
- Proton (9)
- 客戶服務 (9)
- 節目 (9)
- 公司管理 (9)
- 律師 (9)
- 藍天 (9)
- 冒險 (9)
- 放棄 (9)
- 獲得 (9)
- 動視暴雪 (9)
- 壓力 (9)
- 北非 (9)
- 週報 (9)
- 能力 (9)
- 祕訣 (9)
- 無限可能 (9)
- 土耳其 (9)
- 刺客教條 (9)
- 職位 (9)
- 引領 (9)
- DALL-E3 (9)
- 延長 (9)
- 兒童安全 (9)
- 立法 (9)
- 女性領導 (9)
- 數位隱私 (9)
- Max (9)
- 企業市場 (9)
- 翻譯 (9)
- Kickstarter (9)
- 麻省理工學院 (9)
- Aurora (9)
- 數位 (9)
- cryptocurrency (9)
- 金融新聞 (9)
- 高效 (9)
- 印度政府 (9)
- 續航裏程 (9)
- 智慧助理 (9)
- 高品質 (9)
- 利益 (9)
- 蘋果音樂 (9)
- 戴爾 (9)
- Dropbox (9)
- 遊戲機 (9)
- 電動車市場 (9)
- 新方法 (9)
- 波音 (9)
- 旗艦 (9)
- 開源工具 (9)
- 全新 (9)
- 紅杉資本 (9)
- 廣告商 (9)
- 車輛技術 (9)
- DisneyPlus (9)
- 暴雪 (9)
- 股價 (9)
- 軌道 (9)
- 城市 (9)
- VPN (9)
- F-150Lightning (9)
- BTC (9)
- Motional (9)
- 敏捷開發 (9)
- 裁決 (9)
- PlayStation5 (9)
- 跨境支付 (9)
- 文章 (9)
- 決賽 (9)
- WebSummit (9)
- 財務規劃 (9)
- 打折 (9)
- 飛行 (9)
- Peloton (9)
- YouTubeMusic (9)
- 充電網路 (9)
- 實驗室 (9)
- 科技革命 (9)
- 需求 (9)
- 語音技術 (9)
- 鍵盤 (9)
- Ticketmaster (9)
- 領域 (9)
- 內容創作者 (9)
- 編輯 (9)
- 聯合國 (9)
- 數位平臺 (9)
- 熱門話題 (9)
- 歷史新高 (9)
- 新作 (9)
- LindaYaccarino (9)
- 遊戲規則 (9)
- 參議員 (9)
- Qualcomm (9)
- 風波 (9)
- 遊戲工作室 (9)
- Q2 (9)
- 數位科技 (9)
- 綠色科技 (9)
- IndexVentures (9)
- 退款 (9)
- DemoDay (9)
- 處理器 (9)
- MetaAI (9)
- 震驚 (9)
- Python (9)
- DIY (9)
- VertexAI (9)
- 數位健康 (9)
- 駭客事件 (9)
- 加密專案 (9)
- 10 億美元 (9)
- 資本市場 (9)
- 新遊戲 (9)
- 電動滑板車 (9)
- 競爭分析 (9)
- 洩露 (9)
- 堡壘之夜 (9)
- GoogleI/O (9)
- 創造 (9)
- 生成式人工智慧技術 (9)
- EV (9)
- 授權 (9)
- 宕機 (9)
- 可持續性 (9)
- 智慧系統 (9)
- 挪威 (9)
- Shutterstock (9)
- 數位銀行 (9)
- 定價 (9)
- 電子書 (9)
- 炒作 (9)
- 減價 (9)
- 餐廳 (9)
- 深度探索 (9)
- 股票交易 (9)
- 角色 (9)
- 作者 (8)
- 轉向 (8)
- 報名 (8)
- 超值 (8)
- 替代幣 (8)
- 拍攝 (8)
- 企業文化 (8)
- 合成資料 (8)
- 產業 (8)
- 資料收集 (8)
- 市場份額 (8)
- 車輛科技 (8)
- AI 代理 (8)
- 科技政策 (8)
- 科技展 (8)
- 設定 (8)
- 網路趨勢 (8)
- 萊特幣 (8)
- 影片平臺 (8)
- 蘋果智慧 (8)
- 多語言 (8)
- 考驗 (8)
- 科技創業 (8)
- Jumia (8)
- 公開 (8)
- 幻覺 (8)
- FireTV (8)
- AGI (8)
- 王國之淚 (8)
- 角色扮演 (8)
- MWC2024 (8)
- Okta (8)
- SAP (8)
- 亮點 (8)
- 數位市場 (8)
- Poe (8)
- 家用機器人 (8)
- 欺騙 (8)
- 安全研究 (8)
- 東南亞 (8)
- 電子競技 (8)
- GamesBeatNext (8)
- 通訊軟體 (8)
- Google 助理 (8)
- Bolt (8)
- 技術展示 (8)
- 案件 (8)
- notion (8)
- 網路服務 (8)
- Flipboard (8)
- WeWork (8)
- 盛會 (8)
- 醫療 (8)
- 開發者大會 (8)
- 停止 (8)
- 制裁 (8)
- 吸引力 (8)
- 大裁員 (8)
- 企業安全 (8)
- 線上購物 (8)
- 禮物 (8)
- GoogleDocs (8)
- 框架 (8)
- 社交應用 (8)
- 人工智慧功能 (8)
- 無線 (8)
- 經典 (8)
- 影像處理 (8)
- 勝利 (8)
- 影片分享 (8)
- 可摺疊手機 (8)
- chatbot (8)
- 騰訊 (8)
- 資安事件 (8)
- 折疊手機 (8)
- 雲端技術 (8)
- 深度偽造 (8)
- 數位銷售 (8)
- 網路行銷 (8)
- Twilio (8)
- 導演 (8)
- 汽車新聞 (8)
- 約會 (8)
- 矚目 (8)
- 小米 (8)
- 版本 (8)
- 女性領袖 (8)
- 聯邦政府 (8)
- 科技企業 (8)
- 庫存 (8)
- 付款 (8)
- iOS 應用程式 (8)
- 時間 (8)
- Nothing (8)
- 創作者經濟 (8)
- 推遲 (8)
- 機器人吸塵器 (8)
- PanosPanay (8)
- 發現 (8)
- 智慧音箱 (8)
- 記者 (8)
- 效率 (8)
- RocketLab (8)
- 加入 (8)
- 零售 (8)
- 挑戰者 (8)
- 配件 (8)
- 檔案 (8)
- 羅賓漢 (8)
- AI 代理人 (8)
- 轉移 (8)
- 機器計程車 (8)
- kindle (8)
- 網路平臺 (8)
- 員工福利 (8)
- 帳號 (8)
- 文字轉語音 (8)
- 通話 (8)
- WGA (8)
- 財務 (8)
- 逮捕 (8)
- 技術革命 (8)
- Paytm (8)
- FAA (8)
- tweetdeck (8)
- 標籤 (8)
- 夏季 (8)
- OLED (8)
- Cloudflare (8)
- 交通安全 (8)
- GDPR (8)
- 程式碼 (8)
- 揭密 (8)
- 參加 (8)
- Clubhouse (8)
- GoogleMaps (8)
- 道德 (8)
- 充電站 (8)
- 科技突破 (8)
- 法規 (8)
- 文化 (8)
- 車型 (8)
- Astrobotic (8)
- DMA (8)
- 民主化 (8)
- 角色扮演遊戲 (8)
- 搜尋體驗 (8)
- 網路技術 (8)
- AI 科技 (8)
- 康卡斯特 (8)
- 平板 (8)
- 頭盔 (8)
- 雷蛇 (8)
- 影音串流 (8)
- 牛市 (8)
- 大眾汽車 (8)
- 風投公司 (8)
- 人 (8)
- 書籍 (8)
- 立法者 (8)
- 地球 (8)
- Teams (8)
- 技術影響 (8)
- 碳中和 (8)
- 網購 (8)
- 控制器 (8)
- 000 美元 (8)
- TuSimple (8)
- 網路科技 (8)
- 拒絕 (8)
- 辯論 (8)
- 攝影機 (8)
- Bungie (8)
- Affirm (8)
- 撤銷 (8)
- 發布會 (8)
- 英雄聯盟 (8)
- 觀眾 (8)
- 釋出會 (8)
- TCDisrupt (8)
- 納斯達克 (8)
- 華碩 (8)
- Ultra2 (8)
- 變化 (8)
- 出版商 (8)
- 內容審查 (8)
- 國際市場 (8)
- 低成本 (8)
- Midjourney (8)
- TechCrunchEarlyStage2024 (8)
- 科技進步 (8)
- 資產管理 (8)
- 零售商 (8)
- Tesla (8)
- 撤回 (8)
- WWDC2024 (8)
- 家居科技 (8)
- 人才 (8)
- 股票市場 (8)
- 法律訴訟 (8)
- Prosus (8)
- Chainlink (8)
- iPhone14 (8)
- AI 影象生成器 (8)
- 清單 (8)
- 專利 (8)
- 頭戴式耳機 (8)
- 集體訴訟 (8)
- 技術進步 (8)
- 創業戰場 (8)
- 社會運動 (8)
- GeForceNow (8)
- 災難 (8)
- 社群平臺 (8)
- 車主 (8)
- 遊戲界 (8)
- 交易金額 (7)
- 復甦 (7)
- 增加 (7)
- 編劇 (7)
- 獎金 (7)
- 早鳥優惠 (7)
- 調整 (7)
- 企業併購 (7)
- 愛情 (7)
- 遊戲串流 (7)
- 智慧對話 (7)
- 公開市場 (7)
- Podcast (7)
- 開發商 (7)
- 密碼管理器 (7)
- Oura (7)
- 續航力 (7)
- 零售業 (7)
- 種族歧視 (7)
- 概念 (7)
- HorizonWorlds (7)
- 顧客 (7)
- 玩具 (7)
- UAW (7)
- 無人車 (7)
- 註冊 (7)
- Hulu (7)
- Polygon (7)
- 聚焦 (7)
- 兒童保護 (7)
- 個人檔案 (7)
- MetaQuest (7)
- 深科技 (7)
- 射擊遊戲 (7)
- InstagramThreads (7)
- 革命性 (7)
- 廣告收益 (7)
- 人才招聘 (7)
- 責任 (7)
- 自動化工具 (7)
- Arc 瀏覽器 (7)
- 解釋 (7)
- 反壟斷訴訟 (7)
- 新增功能 (7)
- Walmart (7)
- 恐怖遊戲 (7)
- 職場 (7)
- 送貨 (7)
- venturecapital (7)
- 商業計劃 (7)
- 車禍 (7)
- 個人資訊 (7)
- Surface (7)
- 祕密武器 (7)
- 健康監測 (7)
- 建築科技 (7)
- 核能 (7)
- 串流平臺 (7)
- 超導體 (7)
- 花費 (7)
- firefox (7)
- Web3 遊戲 (7)
- 百度 (7)
- 社群互動 (7)
- 感測器 (7)
- FaceTime (7)
- 更名 (7)
- 鬥爭 (7)
- 美國證券交易委員會 (7)
- 深偽影片 (7)
- 投資人 (7)
- M3 (7)
- AI 動力 (7)
- 蘋果地圖 (7)
- 工作室 (7)
- 熱門 (7)
- 影象 (7)
- 對抗 (7)
- 送貨服務 (7)
- 閱讀 (7)
- 好處 (7)
- 穩定 (7)
- 國家安全 (7)
- 風格 (7)
- 打造 (7)
- Showtime (7)
- AI 研究 (7)
- 搶購 (7)
- 影片編輯 (7)
- 升溫 (7)
- 安全風險 (7)
- VinFast (7)
- 選項 (7)
- 印度科技 (7)
- iPadPro (7)
- 保險科技 (7)
- 政治廣告 (7)
- 建議 (7)
- ServeRobotics (7)
- 奇蹟 (7)
- 餐飲科技 (7)
- HPE (7)
- 網站最佳化 (7)
- 手機科技 (7)
- 2026 年 (7)
- 延期 (7)
- 送貨機器人 (7)
- 網站設計 (7)
- 暴漲 (7)
- 氫能 (7)
- 崩盤 (7)
- 爆料 (7)
- 全球市場 (7)
- 賓士 (7)
- 數位工具 (7)
- GoogleMeet (7)
- StabilityAI (7)
- 企業科技 (7)
- 手機支付 (7)
- 女性健康 (7)
- 訂單 (7)
- 心理學 (7)
- 產品設計 (7)
- Starliner (7)
- 太空探險 (7)
- 發售日期 (7)
- 業績 (7)
- 太空公司 (7)
- 網頁應用程式 (7)
- 凱迪拉克 (7)
- Lime (7)
- IntuitiveMachines (7)
- 使用方法 (7)
- 國防科技 (7)
- 軍事科技 (7)
- 公告 (7)
- Computex (7)
- 議員 (7)
- 模組化 (7)
- 生活方式 (7)
- 證實 (7)
- 特色 (7)
- 交通創新 (7)
- 競爭力 (7)
- 開啟 (7)
- 爆紅 (7)
- 禁用 (7)
- 中國科技 (7)
- Fidelity (7)
- 黑暗模式 (7)
- 提示 (7)
- Ray-Ban (7)
- 福特汽車 (7)
- 可持續 (7)
- 蜘蛛人 (7)
- SoftBank (7)
- 帳戶 (7)
- Inflection (7)
- 檢測 (7)
- AI 機器人 (7)
- 明星 (7)
- 新革命 (7)
- 跨平臺 (7)
- 早鳥票 (7)
- Gogoro (7)
- 披露 (7)
- 山姆·奧特曼 (7)
- Alphabet (7)
- 商業化 (7)
- 現金 (7)
- 翻新 (7)
- macOSSonoma (7)
- 合規 (7)
- 判刑 (7)
- 破解 (7)
- 公測 (7)
- AI 法規 (7)
- Aptos (7)
- 舞臺議程 (7)
- 終結 (7)
- 慶祝 (7)
- 音效 (7)
- 交付 (7)
- 裁減 (7)
- 試玩 (7)
- 會計 (7)
- 北美 (7)
- 羅布洛克斯 (7)
- 決定 (7)
- 展望 (7)
- 英國政府 (7)
- 埃及 (7)
- 優步 (7)
- 行業趨勢 (7)
- 流媒體 (7)
- AI 政策 (7)
- 美國制裁 (7)
- AI 引擎 (7)
- 比賽 (7)
- 導航 (7)
- Lightspeed (7)
- Nuro (7)
- 技術投資 (7)
- ShibaInu (7)
- NFLSundayTicket (7)
- 通訊 (7)
- 行政命令 (7)
- 狗狗幣 (7)
- 試用 (7)
- 價格降低 (7)
- AI 藝術 (7)
- 演進 (7)
- Vimeo (7)
- 辯護 (7)
- 獲得資金 (7)
- 馬克·安德森 (7)
- 財報 (7)
- 賠償 (7)
- 谷歌 (7)
- 數位藝術 (7)
- 網路文化 (7)
- 阿凡達 (7)
- Quora (7)
- 女性創業者 (7)
- M2Ultra (7)
- LLaMA2 (7)
- AR 技術 (7)
- 高速公路 (7)
- Android 應用程式 (7)
- 健康生活 (7)
- 最佳選擇 (7)
- 現代 (7)
- 最低價 (7)
- 夢想 (7)
- 臉書 (7)
- Echo (7)
- 強化學習 (7)
- 建造 (7)
- 思考 (7)
- 資金籌措 (7)
- 擴充套件業務 (7)
- 金融創新 (7)
- 浪潮 (7)
- 驚艷 (7)
- 專員 (7)
- 成功祕訣 (7)
- 數位廣告 (7)
- 攻略 (7)
- Office (7)
- 德克薩斯州 (7)
- 承包商 (7)
- 快速 (7)
- StackOverflow (7)
- 火災 (7)
- 財富 (7)
- 降低 (7)
- 機器狗 (7)
- SUV (7)
- Carta (7)
- 焦點 (7)
- 安全平臺 (7)
- 使用體驗 (7)
- 研究者 (7)
- 認證 (7)
- 電視劇 (7)
- VMware (7)
- 加密市場 (7)
- 人工智慧工具 (7)
- 星艦 (7)
- 撰寫 (7)
- 蘋果電視 (7)
- 科學 (7)
- 股份出售 (7)
- 維珍銀河 (7)
- cybersecurity (7)
- 運動 (7)
- GooglePhotos (7)
- 啟動 (7)
- Linktree (7)
- H-1B 簽證 (7)
- 名單 (7)
- JonyIve (7)
- 超級計算機 (7)
- 第三季度 (7)
- 飛利浦 Hue (7)
- 巴黎 (6)
- 記憶體 (6)
- Web3.0 (6)
- 紐約地鐵 (6)
- AppleTV (6)
- 英國監管機構 (6)
- 監禁 (6)
- OpenSea (6)
- 超級瑪利歐 (6)
- D 輪融資 (6)
- 聯絡 (6)
- 願景 (6)
- 真人版 (6)
- 機器人學習 (6)
- TechCrunchLive (6)
- AI 熱潮 (6)
- Mercury (6)
- 身份取證 (6)
- 藍圖 (6)
- 特價優惠 (6)
- 自由工作者 (6)
- 音樂串流平臺 (6)
- neuralink (6)
- 動漫 (6)
- 精彩 (6)
- 比特幣 ETF (6)
- 克拉納 (6)
- TCEarlyStage2024 (6)
- 移民 (6)
- RaspberryPi (6)
- 禮物推薦 (6)
- 利器 (6)
- AI 新創 (6)
- 總部 (6)
- 市場潛力 (6)
- 可信度 (6)
- 億萬富翁 (6)
- 電動車製造商 (6)
- Quest (6)
- 創新策略 (6)
- 新模型 (6)
- GalaxyZFlip5 (6)
- Lucid (6)
- 建築 (6)
- 現代戰爭 III (6)
- 安克 (6)
- 卡巴斯基 (6)
- 交易者 (6)
- Getir (6)
- 銷售額 (6)
- 買賣 (6)
- PM (6)
- 退休 (6)
- 聆聽 (6)
- 法院 (6)
- 數位生活 (6)
- 暴跌 (6)
- ModelY (6)
- 鳳凰城 (6)
- 電馭叛客 2077 (6)
- 工會 (6)
- Box (6)
- 車輛安全 (6)
- 影片生成器 (6)
- HubSpot (6)
- 方式 (6)
- 購物體驗 (6)
- 社區 (6)
- 貝塞斯達 (6)
- 應對策略 (6)
- 艾隆·馬斯克 (6)
- 音樂推薦 (6)
- terraform (6)
- 防範 (6)
- MattMullenweg (6)
- 自訂 (6)
- 觀點 (6)
- 折扣優惠 (6)
- 網路監控 (6)
- 開放原始碼 (6)
- 商業趨勢 (6)
- VR 遊戲 (6)
- iCloud (6)
- 網頁設計 (6)
- 意義 (6)
- 隱藏 (6)
- QED (6)
- Rippling (6)
- 大學生 (6)
- 行業 (6)
- 內幕 (6)
- 個人電腦 (6)
- 政治影響 (6)
- 網友 (6)
- XboxSeriesS (6)
- 手遊 (6)
- 消費者保護 (6)
- 理解 (6)
- 規模 (6)
- Skydio (6)
- 價格下調 (6)
- 創立 (6)
- 簽證 (6)
- 規格 (6)
- 確認 (6)
- 大資料 (6)
- 要求 (6)
- Ola (6)
- ESG (6)
- 印度新創公司 (6)
- 瑞波幣 (6)
- WearOS (6)
- 模擬 (6)
- 六月 (6)
- 社交應用程式 (6)
- 重要 (6)
- 航天科技 (6)
- 開始 (6)
- 構建 (6)
- Archer (6)
- 保險 (6)
- 投資基金 (6)
- 核聚變 (6)
- AmazonPrimeDay (6)
- 專家警告 (6)
- 亞馬遜 Prime (6)
- 實況主 (6)
- PlayStationPortal (6)
- MIT (6)
- 語音辨識 (6)
- ESPN (6)
- 新法案 (6)
- RX7800XT (6)
- 樂趣 (6)
- 新舉措 (6)
- 零件 (6)
- Astra (6)
- 拆分 (6)
- 勞動力 (6)
- 創造力 (6)
- 飆漲 (6)
- 娛樂科技 (6)
- 體育賽事 (6)
- 反壟斷案 (6)
- 一加 (6)
- 身臨其境 (6)
- 3D (6)
- MacStudio (6)
- 新車發布 (6)
- Dogecoin (6)
- 頭像 (6)
- 辨識 (6)
- 濫用 (6)
- 中國駭客 (6)
- 增強 (6)
- 藥物研發 (6)
- Circle (6)
- 賣家 (6)
- Hotstar (6)
- visionOS (6)
- 雲原生 (6)
- 視覺效果 (6)
- 開源技術 (6)
- 加密錢包 (6)
- RiotGames (6)
- 背後故事 (6)
- 低價 (6)
- 8BitDo (6)
- 健身 (6)
- 標準 (6)
- 開放銀行 (6)
- iPadOS (6)
- CPU (6)
- 桌上型 (6)
- 程式設計助手 (6)
- 回收 (6)
- 電池工廠 (6)
- Shorts (6)
- 共享經濟 (6)
- 金融科技公司 (6)
- 自動生成 (6)
- 激增 (6)
- 資金投入 (6)
- UK (6)
- 演變 (6)
- DoKwon (6)
- 新一輪融資 (6)
- 訪談 (6)
- 安全功能 (6)
- 遊戲裝置 (6)
- 安全工具 (6)
- 停用 (6)
- Neeva (6)
- 梅賽德斯 (6)
- 預算 (6)
- 深度解析 (6)
- 資金管理 (6)
- 市場動態 (6)
- Play 商店 (6)
- 挫折 (6)
- Excel (6)
- 普及化 (6)
- 影片創作 (6)
- 舒適 (6)
- 隱私監管 (6)
- 雲端安全 (6)
- Dojo (6)
- 向量資料庫 (6)
- 檢視 (6)
- KhoslaVentures (6)
- 公佈 (6)
- 上傳 (6)
- 影像辨識 (6)
- TrueAnomaly (6)
- 訂閱人數 (6)
- 裏程碑 (6)
- 未來技術 (6)
- HashiCorp (6)
- 拓展 (6)
- 停業 (6)
- 音樂科技 (6)
- 照片編輯 (6)
- 淘汰 (6)
- 系統故障 (6)
- 大揭密 (6)
- 創新思維 (6)
- 奇幻 (6)
- 安巴尼 (6)
- 遠距工作 (6)
- Atlas (6)
- 排行榜 (6)
- 科技新創 (6)
- 主播 (6)
- 影象生成器 (6)
- 現身 (6)
- ChromeOS (6)
- 大規模 (6)
- 7700XT (6)
- 應用程式更新 (6)
- Disney (6)
- 披頭四 (6)
- 最新更新 (6)
- 性別歧視 (6)
- Truecaller (6)
- 數位助手 (6)
- 音訊 (6)
- 股東 (6)
- 泰勒·斯威夫特 (6)
- 職場文化 (6)
- 清潔能源 (6)
- 失望 (6)
- 合作協議 (6)
- RedwoodMaterials (6)
- 訓練資料 (6)
- 電池技術 (6)
- 模擬器 (6)
- 大會 (6)
- 新報告 (6)
- 獨家 (6)
- TerraformLabs (6)
- 全自動駕駛 (6)
- AI 應用程式 (6)
- 簡報 (6)
- 泄露 (6)
- 瑪利歐 (6)
- 費斯克 (6)
- MatchGroup (6)
- 馬克·祖克伯格 (6)
- 即時翻譯 (6)
- 全新功能 (6)
- Audible (6)
- 戴森 (6)
- 投影機 (6)
- 直播平臺 (6)
- EX30 (6)
- Pixel9 (6)
- 數位音樂 (6)
- 經濟發展 (6)
- 愛爾蘭 (6)
- 蘋果裝置 (6)
- 財務長 (6)
- Plex (6)
- Bird (6)
- 科技禮物 (6)
- 效率工具 (6)
- 美國政治 (6)
- 科技盛會 (6)
- 企業策略 (6)
- 簡單 (6)
- Duolingo (6)
- 商業應用 (6)
- 影片串流 (6)
- 電動車產業 (6)
- 宣傳 (6)
- 細節 (6)
- 創企 (6)
- 西班牙語 (6)
- 數學 (6)
- CoreWeave (6)
- Safari (6)
- 影象處理 (6)
- 音樂創作 (6)
- 早期階段 (6)
- GalaxyZFold5 (6)
- Intuit (6)
- 樂觀 (6)
- 新裏程碑 (6)
- 小說 (6)
- 解密 (6)
- 昂貴 (6)
- 二級市場 (6)
- 破紀錄 (6)
- Llama3 (6)
- 數位金融 (6)
- Metaverse (6)
- 背後原因 (6)
- 配送服務 (6)
- 時間線 (6)
- 反應 (6)
- 聰明 (6)
- QR 碼 (6)
- 前員工 (6)
- 關鍵時刻 (6)
- Withings (6)
- 足球 (6)
- 播放清單 (6)
- 新融資 (6)
- 宇宙 (6)
- 間諜 (6)
- 支付系統 (6)
- AI 服務 (6)
- 無人駕駛汽車 (6)
- 雲安全 (6)
- 證據 (6)
- 介面 (6)
- CapCut (6)
- GoogleBard (6)
- 網路攝影機 (6)
- 聊天功能 (6)
- 耳塞 (6)
- 4K (6)
- 魔法 (6)
- FedNow (6)
- 數量 (6)
- 股價暴跌 (6)
- 遊戲活動 (6)
- 同理心 (6)
- 展覽 (6)
- 自動駕駛車輛 (6)
- 菲斯克 (6)
- 美國聯邦貿易委員會 (6)
- 資源 (6)
- GooglePixelFold (6)
- 社交功能 (6)
- Sophie (6)
- 資料泄露 (6)
- 密碼管理 (6)
- BretTaylor (6)
- 公司動態 (6)
- 勞工權益 (6)
- 付費訂閱 (6)
- 規範 (6)
- 機器手臂 (6)
- 4 億美元 (6)
- 歌曲 (6)
- 預算管理 (6)
- 語言支援 (6)
- 創投公司 (6)
- Captions (6)
- CTO (6)
- 新服務 (6)
- 智慧戒指 (6)
- gamedevelopment (6)
- Grayscale (6)
- 資本 (6)
- 思科 (6)
- 火星 (6)
- 2500 萬美元 (6)
- 套裝 (6)
- 預約 (6)
- 甲骨文 (6)
- 聯邦宇宙 (6)
- Logitech (6)
- SAG-AFTRA (6)
- 筆記 (6)
- Alameda (6)
- HBO (6)
- 歐元 (6)
- iPhone12 (6)
- CISA (6)
- 投資決策 (6)
- DuckDuckGo (6)
- 內部檔案 (6)
- 星界 (6)
- 領導者 (6)
- 零信任 (6)